
Modern businesses depend on real-time data to track competitors, analyze customer behavior, and improve operations. However, manual data collection slows decision-making and increases operational costs.
Web scraping has evolved into an AI-powered enterprise technology that automatically extracts and structures large volumes of web data. The global web scraping market is in the low‑billions (around $1.1-1.3B), while the AI‑driven data extraction market is in the mid‑to‑high single‑digit billions (around $7-8B).
Modern self-healing scraping systems, combined with Robotic Process Automation (RPA), help organizations automate up to 80% of repetitive data tasks. This guide explores modern web scraping architectures, enterprise use cases, AI-powered automation, and compliance strategies in 2026.
Table of Contents
What Is Web Scraping?
Web scraping is an automated software process that extracts structured or unstructured data from online web domains using specialized bots, crawlers, or autonomous AI agents.
Unlike API pathways, which platforms can limit or shut down completely, web scraping reads the visual layer of the web directly. This approach ensures continuous access to public market data.
Modern web data platforms capture a wide range of unstructured elements:
- Product Catalog Telemetry: Pricing metrics, inventory stock status, shipping timelines, and product variants.
- Corporate Profile Structures: Leadership hierarchies, contact information, funding histories, and hiring velocity.
- Financial Ledger Feeds: Live stock values, commodities indices, SEC regulatory disclosures, and macroeconomic announcements.
- Public Sentiment Inputs: Consumer reviews, user forums, and social media commentary.
How Web Scraping Works: The Modern 2026 Data Pipeline
Traditional scrapers used rigid DOM parsing to locate data inside specific HTML tags. When a website updated its design, those older scripts failed immediately.
Modern architectures use Intent-Based Data Extraction, utilizing Large Language Models (LLMs) and computer vision to read web pages contextually, much like a human analyst.
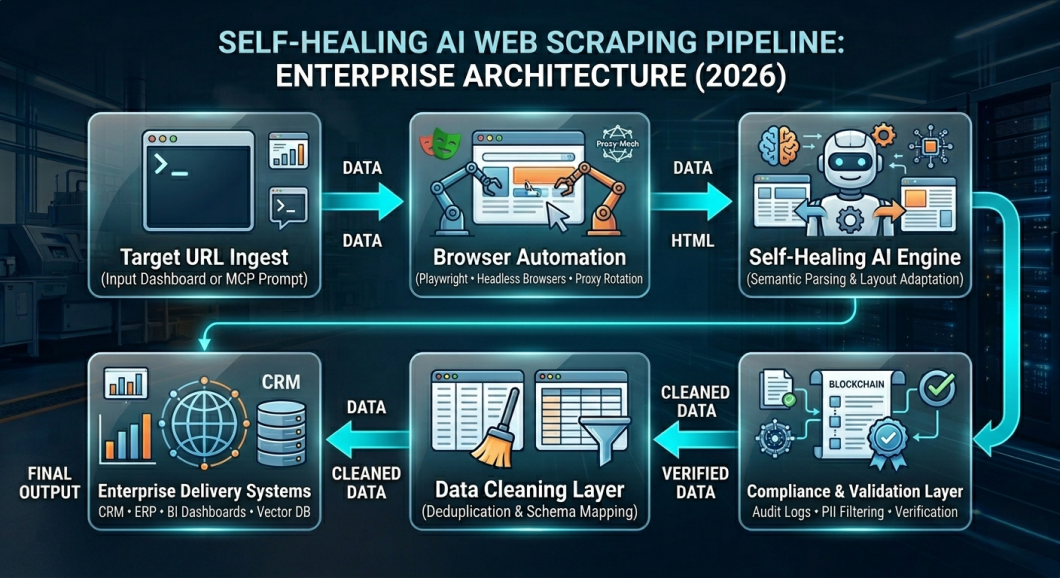
Step 1: Request Ingestion and Browser Access
The process starts when a business enters a target website or sends a natural language request through the Model Context Protocol (MCP). The scraping system then routes the request through a cloud-based headless browser network with automated proxy rotation. This helps the system access websites smoothly and maintain stable performance at scale.
Step 2: AI-Powered Data Extraction
Once the webpage loads, the AI engine identifies the required data points automatically. Unlike traditional scrapers that rely on fixed HTML paths, modern systems understand the page semantically and adapt when website layouts change.
Step 3: Automated Data Cleaning and Normalization
The extracted data is automatically cleaned, formatted, and standardized before entering enterprise systems. This removes duplicate records, fixes formatting issues, and improves data quality for analytics and automation workflows.
Step 4: Compliance Validation and Enterprise Storage
Before the data enters production systems, the platform verifies extraction quality and logs the activity for compliance tracking. The cleaned datasets are then delivered to enterprise platforms such as CRM systems, ERP software, analytics dashboards, cloud warehouses, and vector databases used for AI applications.
This ensures businesses receive structured, reliable, and enterprise-ready data in real time.
Web Scraping vs. APIs: Architectural Comparison
| Architectural Parameter | Web Data Scraping Pipelines | Application Programming Interfaces (APIs) |
| Data Scope and Control | Accesses any public consumer-facing web layout | Restricted to specific endpoints allowed by the platform |
| System Stability | Self-healing AI agents adjust to site layout shifts | Highly stable until a vendor updates or deprecates version endpoints |
| Rate and Volume Caps | Scales dynamically based on cloud proxy network width | Strictly limited by developer subscription tiers and platform paywalls |
| Implementation Overhead | Requires intent-driven layout engines | Requires authentication tokens and custom integration code |
| Primary Enterprise Use | Competitor intelligence, market mapping, AI datasets | Official B2B transactional connections and internal syncs |
Strategic Benefits of Web Data Automation
Modern web data automation helps businesses collect real-time insights faster, reduce manual work, and improve decision-making at scale. Here are some of the key strategic benefits of web data automation:
1. Faster Market Insights
Automated web scraping collects and processes thousands of web records in seconds, helping businesses react faster to market changes.
2. Better Competitive Visibility
Businesses can track customer trends, competitor pricing, reviews, and industry activity directly from public web sources.
3. Reduced Operational Costs
Automation removes repetitive manual research tasks, allowing teams to focus on analytics and business decisions.
4. Scalable Data Collection
Modern scraping systems can monitor millions of web pages daily without major infrastructure limitations.
Top Enterprise Use Cases Driving Industry Growth
1. B2B Lead Generation and Intent Mapping
B2B sales teams rely on high-quality data to identify potential customers. Automated scraping pipelines capture actionable data fields from professional networks, corporate rosters, and regional business registries:
Advanced setups combine basic contact data with Buyer Intent Signals. For instance, a scraper can track corporate job boards to flag companies increasing their spend on specific cloud software tools. This insight allows sales teams to reach out with highly relevant pitches at the optimal time.
2. Alternative Datasets for Quantitative Trading and Finance
In modern financial markets, traditional financial disclosures are often too slow to give investment teams an edge. Quantitative hedge funds and asset managers utilize alternative web data to capture market shifts ahead of traditional reports:
- Real-Time Supply Footprints: Tracking product availability across manufacturing listings to predict supply chain slowdowns.
- NLP Sentiment Scoring: Parsing consumer commentary and regional news feeds through Natural Language Processing (NLP) models to gauge changing brand health.
- Macroeconomic Trend Mapping: Tracking public real estate listings and job portal growth to measure shifting employment across different industries.
3. E-Commerce Dynamics and Real-Time Price Optimization
E-commerce businesses operate in a highly volatile pricing environment where top competitors adjust prices dozens of times a day. Retailers deploy continuous web scraping to map competitor product options, stock changes, and promotional markdowns.
These real-time pricing feeds plug directly into automated repricing algorithms. If a competitor runs low on a high-demand item, your system identifies the stock-out instantly and raises your product’s price within safety margins, protecting your profitability.
4. High-Volume Training Datasets for Generative AI Models
The rapid growth of generative AI tools has created a massive need for clean, structured training data. AI development teams use large-scale scraping infrastructure to gather text, image, and code repositories from public web sources.
Advanced data pipelines convert raw web text into clean markdown files, stripping out website navigation links and advertisement code blocks to produce clean, high-quality inputs for model training.
Technical Challenges in Modern Web Scraping
Modern web scraping systems face several technical and compliance challenges. Businesses must build scalable and intelligent scraping pipelines to maintain reliable data collection.
1. Advanced Anti-Bot Protection and CAPTCHAs
Many websites use CAPTCHA systems, behavioral tracking, and IP monitoring to block automated traffic. To maintain stable access, enterprise scraping platforms use proxy rotation, browser automation, and human-like browsing behavior to reduce detection risks.
2. Website Structure Changes
Traditional scrapers often fail when websites update their layouts or HTML structures. Modern AI-powered scraping systems solve this problem using semantic extraction, allowing them to identify data based on context instead of fixed page elements.
3. Compliance and Data Privacy Regulations
Businesses must ensure their web scraping activities follow privacy regulations such as GDPR and other regional data protection laws. Modern scraping pipelines include compliance checks, rate limiting, robots.txt validation, and data filtering to maintain secure and responsible data collection practices.
Future Horizon: The Evolution Toward Autonomous Web Data Agents
The web data extraction industry is moving away from basic scripts toward fully autonomous data collection systems. The implementation of the Model Context Protocol (MCP) allows AI agents to interact with the web dynamically.
Future scraping engines will not need explicit instructions for specific websites. Instead, users can give a high-level goal in natural language, such as: “Track pricing for all electronic components across major European manufacturing hubs and flag any supply chain shifts.” The autonomous AI agent will then independently discover relevant web sources, handle complex navigation flows, bypass anti-bot systems, and deliver structured, production-ready analytics datasets.
Conclusion
Web scraping has evolved from a basic data-gathering technique into a critical, enterprise-grade data infrastructure. Modern web data collection combines self-healing AI agents with powerful browser automation to deliver reliable, real-time insights across various competitive industries, including finance, travel, e-commerce, and artificial intelligence.
By pairing automated web data extraction with Robotic Process Automation, businesses can completely automate manual research workflows, remove human errors, and react faster to changing market conditions.
As data continues to drive global business strategy, enterprises that implement scalable, compliant, and intelligent web scraping architectures will capture a significant competitive advantage in the modern digital economy.
FAQs
1. What is AI-powered web scraping?
AI-powered web scraping is the automated extraction of web data using artificial intelligence tools that read, interpret, and structure online information in real time for business use.
2. How does AI improve web scraping?
AI improves web scraping by enabling semantic understanding of web pages, allowing systems to extract data accurately even when website layouts change or HTML structures are updated.
3. What are the benefits of web scraping for businesses?
Web scraping helps businesses gain real-time market insights, monitor competitors, reduce manual research effort, automate data collection, and improve decision-making speed.
4. Web scraping vs APIs: what is the difference?
Web scraping extracts public data directly from websites, while APIs provide limited, structured access through predefined endpoints. Scraping offers broader data coverage, while APIs offer stability.
5. What are the challenges of web scraping?
The main challenges in web scraping are anti-bot systems, CAPTCHAs, changing website structures, and compliance with data privacy laws such as GDPR and regional regulations.