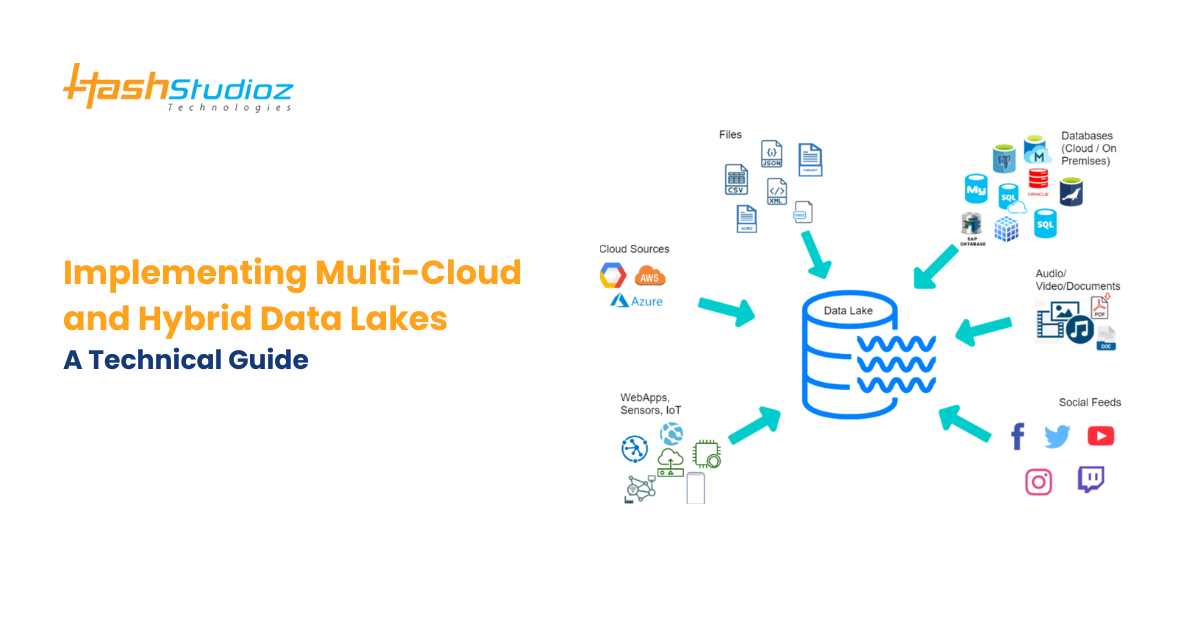
Enterprises today generate vast volumes of data from multiple sources, requiring scalable and efficient storage solutions. Multi-cloud and hybrid data lakes offer a way to handle, process, and analyze massive datasets across various cloud environments while ensuring flexibility, security, and compliance. However, implementing such architectures comes with technical challenges that require a strategic approach.
- 80% of enterprises use a hybrid cloud strategy.
- 90% of organizations struggle with data integration across clouds.
- 60% of companies cite security as a major challenge in hybrid architectures.
Table of Contents
Understanding Multi-Cloud Data and Hybrid Data Lakes
In modern enterprise data management, organizations are increasingly adopting multi-cloud and hybrid data lake architectures to enhance flexibility, scalability, and security. These approaches allow businesses to efficiently store, manage, and analyze vast amounts of data across multiple environments.
What is a Multi-Cloud Data Lake?
A multi-cloud data lake is a data storage architecture where data is distributed across multiple cloud platforms, such as AWS, Google Cloud, and Microsoft Azure. This approach helps organizations:
- Avoid vendor lock-in by utilizing different cloud providers.
- Enhance redundancy and disaster recovery by distributing data across multiple clouds.
- Optimize costs by selecting cloud providers with the best pricing and performance for specific workloads.
- Leverage cloud-specific features for analytics, machine learning, and processing capabilities.
What is a Hybrid Data Lake?
A hybrid data lake combines on-premises infrastructure with public cloud services, allowing businesses to store sensitive or regulatory-compliant data on-premises while utilizing cloud services for scalability and advanced analytics. Key advantages of a hybrid data lake include:
- Enhanced control and security over critical business data.
- Optimized performance by keeping frequently accessed data closer to on-premises applications.
- Regulatory compliance by ensuring data sovereignty and adherence to industry standards.
- Flexibility to scale into the cloud for analytics, AI/ML workloads, and distributed data processing.
Differences Between Multi-Cloud and Hybrid Data Lakes
| Aspect | Multi-Cloud Data Lake | Hybrid Data Lake |
| Storage Location | Public clouds (AWS, Azure, GCP, etc.) | Combination of on-premises and cloud |
| Primary Use Case | Avoid vendor lock-in, improve redundancy | Maintain sensitive data on-premises, scale using cloud |
| Security & Compliance | Managed within cloud providers’ security framework | Requires additional security measures for on-premises infrastructure |
| Data Governance Complexity | High due to multiple cloud environments | Moderate as some data remains on-premises |
Key Benefits of Multi-Cloud and Hybrid Data Lakes
Organizations adopting multi-cloud and hybrid data lakes gain several advantages in terms of scalability, cost efficiency, security, and operational flexibility. Below are the key benefits of implementing these architectures:
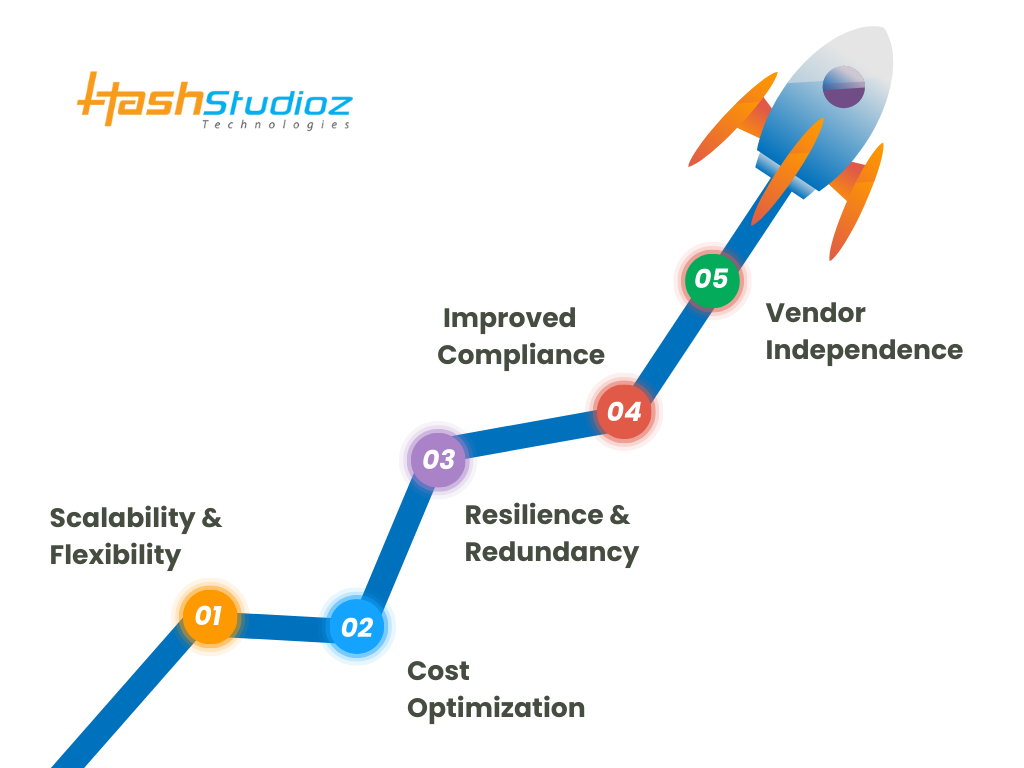
1. Scalability & Flexibility
- Businesses generate vast amounts of data, and scalability is crucial for handling growing workloads.
- Multi-cloud and hybrid data lakes allow organizations to dynamically allocate storage and compute resources across different cloud providers and on-premises infrastructure.
- Enterprises can scale up or down based on demand, ensuring optimal resource utilization without excessive investment in on-premises infrastructure.
2. Cost Optimization
- With multiple cloud providers available, organizations can compare pricing models and select cost-efficient options for storage, processing, and analytics.
- Hybrid data lakes reduce costs by storing frequently accessed data on-premises, eliminating unnecessary cloud storage expenses.
- Multi-cloud strategies enable businesses to leverage cloud-specific discounts, avoiding vendor lock-in and costly data egress fees.
3. Resilience & Redundancy
- Data lakes need high availability and disaster recovery capabilities to ensure business continuity.
- Distributing data across multiple cloud providers prevents single points of failure, enhancing resilience against cloud outages.
- Hybrid architectures allow businesses to maintain on-premises backups for additional redundancy and failover protection.
4. Improved Compliance
- Organizations in regulated industries (e.g., healthcare, finance, and government) must comply with data security laws like GDPR, HIPAA, and CCPA.
- A hybrid data lake allows companies to store sensitive or regulated data on-premises while leveraging the cloud for analytics and big data processing.
- Multi-cloud strategies offer region-based storage options, ensuring compliance with data sovereignty laws.
5. Vendor Independence
- Relying on a single cloud provider creates vendor lock-in, making migrations and cost optimizations difficult.
- Multi-cloud data lakes eliminate dependency on a single vendor, allowing businesses to switch providers based on pricing, performance, or compliance requirements.
- Organizations gain greater control over their infrastructure, reducing risks associated with service disruptions or policy changes by a single provider.
Challenges in Implementing Multi-Cloud and Hybrid Data Lake
While multi-cloud and hybrid data lakes offer numerous advantages, they also introduce several technical and operational challenges. Successfully implementing these architectures requires overcoming issues related to data consistency, security, integration, cost management, and latency. Below are the key challenges organizations face:
1. Data Consistency Issues
- Ensuring data consistency across multiple cloud environments and on-premises systems is complex due to differences in data formats, replication mechanisms, and synchronization methods.
- Data versioning problems can arise if updates are made in one environment but are not reflected in others promptly.
- Organizations must implement real-time data replication, change data capture (CDC), and metadata management strategies to maintain consistency.
2. Security & Compliance Risks
- Maintaining uniform security policies across AWS, Azure, Google Cloud, and on-premises infrastructure is challenging.
- Compliance with GDPR, HIPAA, CCPA, and other regulations requires strict access controls, encryption mechanisms, and audit trails.
- Hybrid data lakes need additional network security layers, such as VPNs, firewalls, and identity management solutions to protect sensitive data.
- Data sovereignty laws may restrict where certain types of data can be stored, requiring organizations to carefully design their storage architecture.
3. Integration Complexity
- Different cloud providers use unique data storage formats, APIs, and processing frameworks, making cross-cloud and on-premises integration difficult.
- ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes need to be adapted to support multi-cloud interoperability.
- Organizations must invest in data integration platforms, middleware, or unified data orchestration tools (e.g., Apache NiFi, Airflow, or Kubernetes) to seamlessly move data between environments.
4. Cost Management
- Without careful planning, multi-cloud architectures can lead to skyrocketing costs due to:
- Data egress fees when transferring data between cloud providers.
- Duplicate data storage across multiple locations.
- Underutilized cloud resources that contribute to unnecessary expenses.
- Organizations must use cost monitoring tools (e.g., AWS Cost Explorer, Google Cloud Billing, Azure Cost Management) to track usage and optimize storage and compute expenses.
5. Latency Concerns
- Data movement across different cloud providers and on-premises environments can introduce high network latency and impact query performance.
- Real-time analytics and AI workloads require low-latency access to data, which can be difficult to achieve in a distributed data lake architecture.
- Solutions like edge computing, caching strategies, and optimized data partitioning can help minimize latency and improve data processing speeds.
Overcoming These Challenges
Organizations can mitigate these challenges by:
- Implementing data synchronization and version control mechanisms to ensure consistency.
- Using centralized security policies and IAM (Identity and Access Management) solutions for access control.
- Adopting hybrid and multi-cloud data integration platforms to streamline data movement.
- Optimizing storage policies to reduce unnecessary data duplication and egress costs.
- Deploying edge computing or caching solutions to improve query performance and reduce latency.
Core Components of Multi-Cloud and Hybrid Data Lake Architectures
A multi-cloud or hybrid data lake consists of multiple layers that work together to store, process, secure, and manage data effectively. These layers include storage, compute, metadata management, security, and governance. Understanding these components is essential for building a scalable, efficient, and compliant data lake.
1. Storage Layer
The storage layer is the foundation of a data lake, responsible for storing structured, semi-structured, and unstructured data. A well-designed storage layer ensures high availability, durability, and cost efficiency.
Types of Storage Solutions in Multi-Cloud and Hybrid Data Lakes:
A. Object Storage
Object storage is the most commonly used storage type in cloud environments due to its scalability, durability, and cost-effectiveness.
- Amazon S3 (AWS) – Highly scalable and durable object storage.
- Google Cloud Storage – Optimized for performance and availability.
- Azure Blob Storage – Suitable for big data and analytics workloads.
B. Distributed File Systems
Distributed file systems support large-scale data storage across multiple machines, enabling high-performance processing and analytics.
- HDFS (Hadoop Distributed File System) – Commonly used in big data frameworks.
- Ceph – An open-source software-defined storage system.
- Lustre – A high-performance file system designed for large-scale workloads.
C. Hybrid Storage Solutions
Hybrid storage solutions allow organizations to combine on-premises and cloud storage, providing seamless data movement and integration.
- NetApp Cloud Volumes – Enables hybrid cloud storage with efficient data management.
- Dell EMC PowerScale – Supports multi-cloud and hybrid data storage needs.
2. Compute Layer
The compute layer is responsible for processing and analyzing data in a multi-cloud or hybrid data lake. This layer ensures that data can be transformed, queried, and analyzed efficiently.
Types of Compute Solutions:
A. Serverless Compute
Serverless computing enables businesses to process data on demand without managing servers, reducing operational overhead.
- AWS Lambda – Supports event-driven execution of code for data transformations.
- Google Cloud Functions – Enables cloud-native data processing.
B. Containerized Workloads
Containers allow for portable, scalable, and consistent data processing across different cloud platforms.
- Kubernetes – Orchestrates containerized applications across cloud and on-premises environments.
- Docker – Enables lightweight and portable compute environments.
C. Distributed Processing Frameworks
For large-scale data processing, distributed frameworks ensure high efficiency.
- Apache Spark – Processes large datasets with in-memory computing.
- Hadoop (MapReduce) – Handles batch data processing across distributed environments.
3. Metadata Management
Metadata management is essential for organizing, discovering, and governing data within a data lake. It ensures data integrity, schema consistency, and efficient query execution.
Key Metadata Management Tools:
A. Data Catalogs
Data catalogs help in discovering and indexing metadata across different data sources.
- AWS Glue Data Catalog – Provides automated schema discovery and metadata storage.
- Apache Atlas – Supports metadata governance and classification in hybrid and cloud environments.
B. Schema Management
Schema management solutions ensure that data structures remain consistent and compliant.
- Apache Hive Metastore – A common metadata repository for Hadoop-based data lakes.
4. Security and Compliance
Security is a critical component in multi-cloud and hybrid data lakes, ensuring data protection, access control, and compliance with industry regulations.
Key Security and Compliance Measures:
A. Data Encryption
Encryption ensures that data remains secure both at rest and in transit.
- AES-256 Encryption – Industry-standard encryption for securing stored data.
- TLS/SSL Protocols – Encrypts data in transit across cloud and on-premises networks.
B. Identity and Access Management (IAM)
IAM ensures that only authorized users and applications can access data.
- Role-Based Access Control (RBAC) – Assigns permissions based on user roles.
- Attribute-Based Access Control (ABAC) – Grants permissions based on user attributes.
5. Governance and Access Control
Governance ensures that data lakes remain compliant, secure, and well-managed. Proper governance controls help in preventing data breaches, ensuring privacy, and meeting regulatory requirements.
Key Governance and Access Control Strategies:
A. Policy-Based Data Access Controls
- Organizations must define who can access which data and under what conditions.
- Automated data masking and anonymization techniques help protect personally identifiable information (PII).
B. Regulatory Compliance Enforcement
Multi-cloud and hybrid data lakes must adhere to various global compliance standards:
- GDPR (General Data Protection Regulation) – Ensures data privacy for EU citizens.
- HIPAA (Health Insurance Portability and Accountability Act) – Protects sensitive healthcare data.
- CCPA (California Consumer Privacy Act) – Regulates data privacy for California residents.
Technical Considerations for Implementation
Designing a multi-cloud and hybrid data lake requires careful planning across various technical aspects, including data ingestion, processing, interoperability, and performance management. Each of these factors ensures scalability, efficiency, and seamless integration across cloud providers and on-premises environments.
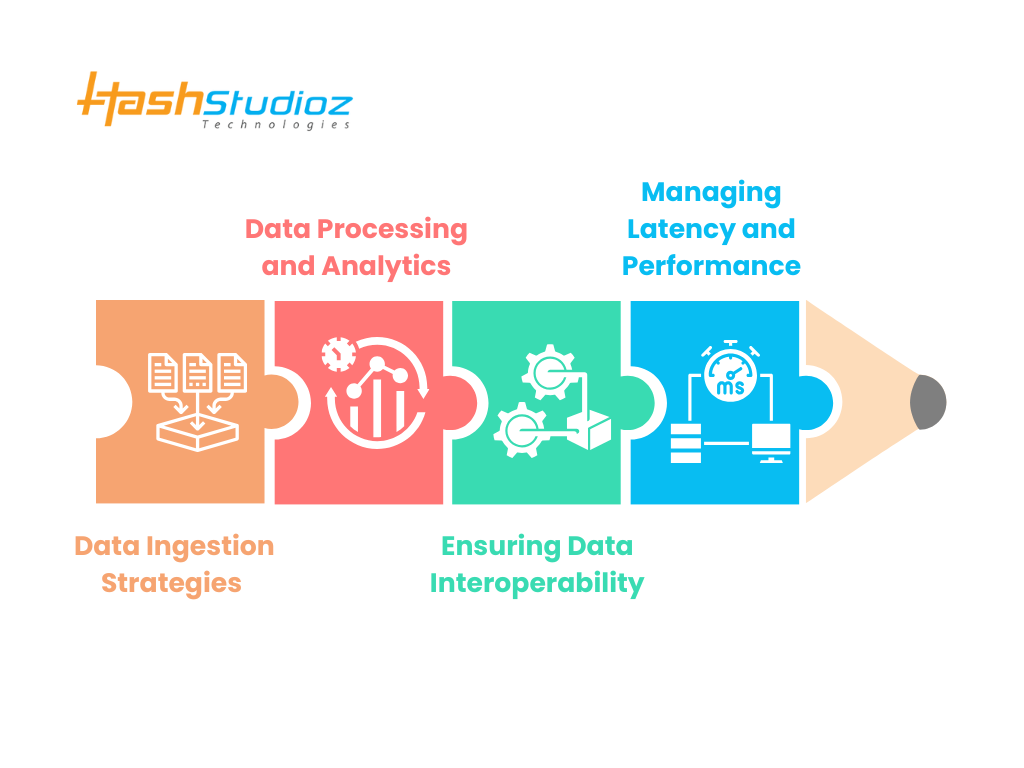
1. Data Ingestion Strategies
Data ingestion is the first step in a data lake pipeline, involving collecting, transferring, and storing data from various sources. The ingestion process must support both batch and real-time streaming methods to accommodate different use cases.
A. Batch Data Ingestion
Batch ingestion processes large volumes of data at scheduled intervals, making it suitable for historical data imports and bulk transfers.
Key Technologies for Batch Ingestion:
- Apache Sqoop – Transfers structured data from relational databases into data lakes.
- AWS Snowball – Moves petabyte-scale data from on-premises systems to the cloud.
- Google Cloud Transfer Service – Enables large-scale batch data transfers into Google Cloud Storage.
B. Streaming Data Ingestion
Streaming ingestion processes data in real time, enabling low-latency analytics, fraud detection, and event-driven applications.
Key Technologies for Streaming Ingestion:
- Apache Kafka – A distributed event streaming platform for real-time data pipelines.
- AWS Kinesis – Processes real-time data streams for analytics and machine learning.
- Google Cloud Pub/Sub – Enables asynchronous messaging between distributed applications.
Choosing the Right Strategy:
- Batch ingestion is ideal for scheduled ETL workflows, business intelligence, and archival storage.
- Streaming ingestion is better suited for real-time analytics, IoT data processing, and event-driven applications.
2. Data Processing and Analytics
Once data is ingested into the data lake, it must be processed, transformed, and analyzed efficiently. The processing layer enables big data analytics, machine learning, and real-time insights.
A. Distributed Data Processing
Distributed processing frameworks enable parallel execution of tasks across multiple nodes, improving performance for large-scale data workloads.
Key Technologies for Distributed Processing:
- Apache Spark – An open-source engine for batch and real-time big data processing.
- Presto – A distributed SQL query engine optimized for large-scale analytics.
- Google BigQuery – A serverless data warehouse with real-time analytics capabilities.
B. Real-Time Analytics
Real-time analytics frameworks enable low-latency data processing for use cases such as fraud detection, monitoring, and anomaly detection.
Key Technologies for Real-Time Analytics:
- Apache Flink – A stream processing framework for real-time data analysis.
- AWS Kinesis Analytics – Processes streaming data using SQL queries and machine learning models.
Choosing the Right Approach:
- Use distributed processing for batch analytics, ETL transformations, and large-scale queries.
- Use real-time analytics for streaming data, IoT use cases, and instant decision-making.
3. Ensuring Data Interoperability
Interoperability ensures that data can be shared, queried, and processed across different platforms and cloud providers. Standardized formats and APIs help maintain seamless data integration.
A. Common Data Formats
Using standardized data formats ensures that data is easily accessible across various analytics tools and cloud environments.
Key Data Formats:
- Parquet – A columnar storage format optimized for query performance and compression.
- Avro – A row-based format with schema evolution support, ideal for streaming data.
- ORC (Optimized Row Columnar) – A format designed for fast read performance in distributed storage.
B. Standardized API Layers
APIs provide a unified interface for data access and management across different environments.
Key API Technologies:
- REST APIs – Enable standard HTTP-based communication between applications.
- GraphQL – Provides flexible and efficient querying capabilities for structured data.
Best Practices for Interoperability:
- Choose common file formats like Parquet or Avro to ensure data portability.
- Implement REST or GraphQL APIs for standardized data access across cloud environments.
4. Managing Latency and Performance
Optimizing latency and performance is critical for efficient data access, processing, and analytics in multi-cloud and hybrid data lakes.
A. Caching Strategies
Caching reduces response times by storing frequently accessed data in memory or high-speed storage.
Key Caching Techniques:
- In-Memory Caching (Redis, Memcached) – Speeds up query performance by keeping data in RAM.
- Query Result Caching (Presto, Spark SQL) – Stores query outputs for reuse, reducing redundant computations.
B. Data Replication
Replicating data across multiple locations ensures high availability, fault tolerance, and reduced latency.
Key Data Replication Methods:
- Cross-Region Replication – Copies data between cloud regions to optimize availability.
- Multi-Cloud Synchronization – Ensures consistency across AWS, Azure, and Google Cloud.
Best Practices for Performance Optimization:
- Implement caching mechanisms to minimize redundant queries and speed up access.
- Use data replication to ensure data availability and reduce cross-region latency.
Choosing the Right Storage Formats and Optimization Strategies
Selecting the appropriate storage format is critical for optimizing the performance, cost, and efficiency of multi-cloud and hybrid data lakes. Different storage formats provide varied advantages in terms of query performance, compression, and schema evolution.
1. Key Storage Formats for Data Lakes
A. Parquet – Optimized for Analytics Workloads
Apache Parquet is a columnar storage format designed to improve query performance and data compression. It is widely used in big data and analytics workloads.
Advantages of Parquet:
- Columnar format allows efficient read performance for analytical queries.
- High compression ratios reduce storage costs.
- Optimized for distributed computing frameworks like Apache Spark, Presto, and Hive.
Best Use Cases:
- Business intelligence and data warehousing
- ETL pipelines and big data analytics
- Machine learning feature stores
B. ORC (Optimized Row Columnar) – High Compression Efficiency
ORC is a highly optimized columnar format primarily used in the Hadoop ecosystem. It provides better compression and faster query execution than many other formats.
Advantages of ORC:
- Higher compression efficiency than Parquet due to lightweight indexing.
- Optimized for Hadoop-based processing frameworks (Hive, Spark, Presto).
- Faster predicate pushdown for quick filtering of data during queries.
Best Use Cases:
- High-performance data lakes on Hadoop clusters
- Cost-efficient storage with superior compression
- Cloud-based big data processing with Hive and Spark
C. Avro – Best for Schema Evolution
Apache Avro is a row-based storage format that excels in schema evolution and data serialization. It is commonly used in streaming applications and data pipelines.
Advantages of Avro:
- Supports schema evolution, making it ideal for frequent data structure changes.
- Compact binary format for fast serialization and deserialization.
- Compatible with streaming platforms like Apache Kafka and AWS Kinesis.
Best Use Cases:
- Real-time data streaming and event-driven applications
- Schema-evolving datasets (e.g., logs, IoT data, or transactional records)
- Efficient data exchange between different applications
2. Optimization Strategies for Data Storage
A. Partitioning Data for Faster Queries
Partitioning divides data into smaller, manageable segments, improving query performance.
Best Practices for Partitioning:
- Use time-based partitions (daily, monthly, yearly) for log and event data.
- Partition by key attributes (e.g., country, department, product category).
- Ensure partition pruning to avoid scanning unnecessary data.
B. Data Compression to Reduce Storage Costs
Compression reduces storage requirements and improves query efficiency.
Common Compression Codecs:
- Snappy – Fast compression/decompression, ideal for real-time workloads.
- Zlib – Higher compression ratio, best for long-term storage.
- LZ4 – Ultra-fast decompression for low-latency analytics.
C. Metadata Management for Efficient Data Retrieval
Metadata management helps organize and catalog data efficiently in a multi-cloud or hybrid data lake.
Key Metadata Tools:
- AWS Glue Data Catalog – Manages metadata for AWS-based data lakes.
- Apache Atlas – Provides data governance and lineage tracking.
- Google Data Catalog – Enables metadata management in Google Cloud environments.
Security Considerations in Multi-Cloud and Hybrid Data Lakes
Security is a critical concern when implementing multi-cloud and hybrid data lakes. Organizations must ensure data protection, access control, and compliance while managing diverse cloud environments.
1. Role-Based and Attribute-Based Access Control (RBAC & ABAC)
Controlling who can access what data is crucial for maintaining data security and governance.
A. Role-Based Access Control (RBAC) – User-Centric Access Management
RBAC assigns permissions based on user roles (e.g., Admin, Analyst, Data Scientist).
- Simplifies access management in large organizations.
- Prevents unauthorized access to sensitive data.
- Commonly used in cloud IAM systems (AWS IAM, Azure AD, Google Cloud IAM).
B. Attribute-Based Access Control (ABAC) – Context-Aware Security
ABAC grants access based on attributes like user identity, data type, location, and time.
- Provides more granular control over data access.
- Ideal for complex, multi-cloud environments with dynamic access needs.
- Examples: AWS Lake Formation, Azure Purview, and Google Cloud Policy Engine.
2. Encryption for Data Protection
Data encryption ensures data confidentiality at rest and in transit.
A. Encrypting Data at Rest
- AES-256 encryption – Standard for securing stored data.
- Cloud-native encryption services – AWS KMS, Azure Key Vault, and Google Cloud KMS.
B. Encrypting Data in Transit
- TLS (Transport Layer Security) 1.2/1.3 secures data moving across networks.
- End-to-end encryption ensures data integrity between hybrid environments.
3. Data Masking & Tokenization for Sensitive Data Protection
A. Data Masking – Preventing Unauthorized Data Exposure
- Use Case: Protecting PII (Personally Identifiable Information) in test environments.
- Techniques: Static masking, dynamic masking (AWS Macie, Azure Data Masking).
B. Tokenization – Secure Data Replacement
Tokenization replaces sensitive data with a unique identifier (token) while storing actual data separately.
- Ideal for payment processing, financial transactions, and compliance-driven industries.
- Example tools: HashiCorp Vault, Google Cloud Tokenization API.
How Data Lake Consulting Services Facilitate Implementation
Implementing a multi-cloud or hybrid data lake is a complex process that requires expertise in cloud architecture, security, and performance optimization. Data Lake Consulting Services play a crucial role in guiding organizations through the design, implementation, and management of efficient and secure data lake environments.
1. Cloud Strategy Development
A well-defined cloud strategy is essential to ensure scalability, cost-efficiency, and resilience in a multi-cloud or hybrid data lake.
How Data Lake Consulting Services Help:
- Assess Business Needs: Identify the best mix of cloud and on-premises infrastructure.
- Cloud Selection & Migration Planning: Choose the optimal cloud providers (AWS, Azure, GCP) based on performance, security, and pricing models.
- Data Lake Architecture Design: Define the storage, compute, and data governance layers.
- Data Integration Strategy: Plan batch and real-time ingestion using tools like Apache Kafka, AWS Glue, or Google Dataflow.
2. Security & Compliance Planning
Security is a major challenge in multi-cloud and hybrid environments. Data Lake Consulting Services help businesses implement best-in-class security measures.
How They Assist:
- Identity & Access Management: Implement RBAC & ABAC to prevent unauthorized data access.
- Data Encryption: Use AES-256 encryption and TLS for securing data at rest and in transit.
- Regulatory Compliance: Ensure adherence to GDPR, HIPAA, SOC 2, and other regulations.
- Threat Detection & Monitoring: Set up cloud-native security tools like AWS GuardDuty, Azure Security Center, and Google Security Command Center.
3. Performance Optimization
Performance is a key factor in ensuring fast data retrieval, efficient analytics, and cost-effective operations.
Key Optimization Strategies Offered by Data Lake Consulting Services:
- Storage Format Optimization: Choose Parquet, ORC, or Avro based on workload requirements.
- Query Performance Tuning: Implement partitioning, indexing, and caching strategies.
- Compute Resource Optimization: Leverage serverless architectures (AWS Lambda, Google Cloud Functions) and Kubernetes for scalable workloads.
- Cost Management Strategies: Optimize storage costs, reduce data transfer fees, and implement lifecycle policies.

Conclusion
Implementing multi-cloud and hybrid data lakes requires a strategic approach that balances scalability, security, and performance. By leveraging the right tools and best practices, organizations can maximize the potential of their data lake while ensuring compliance and cost efficiency.
Frequently Asked Questions
Q1. What are the key differences between multi-cloud and hybrid data lakes?
Multi-cloud data lakes use multiple cloud providers, whereas hybrid data lakes combine on-premises infrastructure with cloud storage.
Q2. How do Data Lake Consulting Services help in implementation?
They assist in architecture design, data security, performance optimization, and cost management.
Q3. What security measures are necessary for multi-cloud and hybrid data lakes?
RBAC, ABAC, encryption, and tokenization ensure secure data access.
Q4. Which cloud platforms support data lakes?
AWS, Azure, and Google Cloud offer comprehensive data lake solutions.
Q5. How can businesses optimize costs in multi-cloud data lakes?
By selecting cost-efficient storage options, reducing data egress fees, and implementing data lifecycle management policies.